Snowflake took the world by storm with a purpose-built, SaaS data analytics cloud for moving data warehouse workloads to the cloud. Microsoft has responded with an ever evolving and improving Azure Synapse Analytics offering.
Following, we dive into some of the similarities and differences between Snowflake and Azure Synapse, focusing on these areas
- PaaS vs. SaaS
- Approach to computing resources
- Approach to querying semi structured files using SQL
- Source controls
- Tools for data integration and transformation
To see demos of both Snowflake and Azure Synapse, watch our on-demand webinar where we compare the two platforms.
Similarities
Both Snowflake and Azure Synapse are modern, cloud-based systems focused on data warehousing. Data warehouse is an excellent use case for the cloud, given its large data requirements and peak computational workloads like nightly ETL runs or peak report and dashboard consumption time frames.
In addition, both products are priced with separate storage and compute costs. Compute resources can scale up, scale down, be started or paused to control costs while delivering enhanced performance when needed.
Both platforms structure data warehouses in relational SQL databases, leveraging columnar storage under the covers to minimize data size growth while delivering excellent performance. In addition, both platforms can be accessed from a variety of data visualization tools for delivering insights to end users.

PaaS vs. SaaS
One initial difference to note is that these systems are sold in slightly different ways. Snowflake is delivered as SaaS that runs on top of Azure, AWS or Google clouds. An abstraction layer separates the Snowflake compute credits and storage you pay for from the actual underlying storage and compute cloud provided resources and costs. This approach enables the exact same Snowflake experience to run on top of any of the three major cloud providers. Being able to co-locate your Snowflake tenant with existing large cloud data volumes should minimize bandwidth costs that going outside of that cloud provider would incur.
Azure Synapse is primarily a Platform as a Service (PaaS) solution with free Azure Synapse Workspace development environment on top of those resources. You ultimately end up paying for Azure resources. The benefit of this approach is that other Azure resources such as Azure Active Directory and Power BI are tightly coupled when using Azure Synapse for data warehousing.

Computing resources
The biggest difference between the two platforms is seen with how they approach compute resources. While both platforms allow the creation of SQL databases for data warehousing, how they act on that database through compute resources is unique.

Snowflake has completely decoupled the SQL databases created in Snowflake from the compute resources that load or query those SQL databases. This means any compute resource, called a “warehouse” in Snowflake, can operate on any SQL database in Snowflake. This approach enables multiple compute resources to concurrently use the same database. For example, one compute resource could be loading data while another is querying data for reports without any concerns about the performance of one job impacting the other job.
Another killer feature of Snowflake’s compute resources is the ability to auto-pause a resource after a period of inactivity. Resources will resume when queries show up again. This can really keep accidental spend in line when someone forgets to turn off a very large compute resource being used for ad hoc analysis.
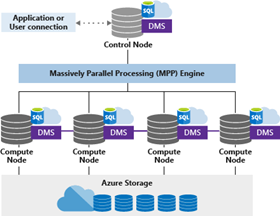 Azure Synapse takes a different approach to computing power. A dedicated SQL pool is required to create a long-lived SQL database suitable for data warehousing. That SQL database is tightly coupled to the dedicated SQL pool compute resource. The dedicated SQL pool must be running to access the SQL database associated with it. Multiple SQL pools cannot access the same SQL database at the same time. Instead, Azure Synapse implements a massively parallel processing engine pattern that will distribute SQL commands across a range of compute nodes based on your selected SQL pool performance level.
Azure Synapse takes a different approach to computing power. A dedicated SQL pool is required to create a long-lived SQL database suitable for data warehousing. That SQL database is tightly coupled to the dedicated SQL pool compute resource. The dedicated SQL pool must be running to access the SQL database associated with it. Multiple SQL pools cannot access the same SQL database at the same time. Instead, Azure Synapse implements a massively parallel processing engine pattern that will distribute SQL commands across a range of compute nodes based on your selected SQL pool performance level.
Dedicated SQL pools can be paused and resumed, but this is currently a manual or API based operation.
Querying semi-structured files using SQL
Semi-structured data like JSON and XML have become prevalent file formats over the past several years. These file formats allow operational systems to export arrays of complex objects that retain hierarchy and nesting concepts. Querying object attributes directly from these semi-structured files is not supported by the base SQL language, but SQL extensions have been added to both systems to support querying slices of semi-structured data in a logical way.
Below we focus on each system’s approach to JSON files.
Microsoft added support to Synapse SQL for two SQL extensions that query JSON data from strings. The JSON_VALUE function accepts JSON text and a path to the property to extract. Alternatively, you can use the OPENJSON function to parse out objects and properties.
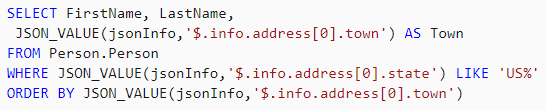

Snowflake’s approach involves pulling JSON data into a VARIANT data type, then using its PARSE_JSON function. At that point, JSON data can be intuitively accessed using dot notation or bracket notation.
![]()
![]()
Source control
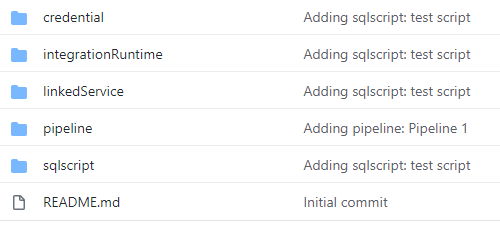
Azure Synapse has native source control integration to GitHub and Azure DevOps Git, both of which are Microsoft owned. By configuring a git repository for your Azure Synapse workspace, artifacts like SQL scripts and ADF pipelines will be committed to the repo when the workspace is saved and published. This tightly integrated approach does not preclude you from setting up a different source control system, but it won’t be as easy to enforce as the native approach. A screenshot of GitHub folders generated by Azure Synapse is seen below.
Snowflake does not currently offer a built-in source control connector from within its development environment. SQL scripts could be saved to local files and committed to any source control system. Alternatively, some third-party systems appear to leverage Snowflake API events to sync changes between Snowflake and source control systems, but with little control of what is a necessary commit. Either way, some manual action is likely needed, meaning a bit of a workflow or process must be established and maintained by your organization—versus the automatic nature of Microsoft’s integrated approach.
In either case, once scripts hit a source control system, triggers and actions could be used to create a typical CI/CD process and release pipeline.
Tools for data integration and transformation
Similar to each platform’s source control capabilities, Azure Synapse tightly integrates Azure Data Factory as a data integration and transformation tool. Snowflake, on the other hand, leans heavily on third-party tools for these capabilities.
Azure Data Factory pipelines are robust and extensible, being able to call out to a variety of other functionality through Databricks or Azure Functions. Azure Synapse workspaces roll in monitoring capabilities for pipeline runs and triggers. On-prem data can be securely accessed by installing an Integration Runtime gateway, which can then be called by the pipelines.
Snowflake opts to provide APIs and a variety of drivers for data integration partners to use within their solutions. A handful of these partners allow trials from within Snowflake’s partner connect feature, making these tools feel a bit more integrated with the overall platform. You may discover a better tool for your specific use cases from their partners. You can also use Azure Data Factory here if desired.
Recap
Both Snowflake and Azure Synapse provide a modern approach to cloud-based data warehousing in a SQL database. Both systems are highly scalable and allow for some level of consumption-based costing reflecting data storage and compute resources.
Each has some unique features and approaches that may make one product more suitable for your organization over the other. Enterprises that are already highly using Azure, AD and Power BI may find the tight integration of Azure Synapse helpful. Organizations that are cloud agnostic or want to retain the ability to move between clouds easily will like Snowflake’s ability to run on any of the three major platforms. The simplicity of a dedicated, resizable SQL pool tying to one database may appeal to some organizations, whereas other organizations may desire the ability for multiple compute warehouses to act on the same Snowflake SQL database simultaneously and without contention.
These systems are wide and complex. There are many additional platform capabilities we didn’t dive into here – sharing data with partners, pulling in external data sets or copying databases for testing.
Senturus is both a Snowflake and Microsoft partner. We can provide unbiased help determining the right data platform for your organization. Contact us.