Ah, IBM Cognos Framework Manager. For nearly 20 years it has been the go-to tool for Cognos Report modelers to create packages for authoring. Solid, comfortable and an integral part of the product line, it seemed like Framework Manager would be around forever. But what is this news you may have heard…that IBM will not be doing any new development on the product? What, you wonder, shall we use now to create models and packages? Welcome to data modules. The next gen Cognos modeling tool still has a few wrinkles to iron out, but overall it has lots to offer. We touch on some of the strengths and weakness of data modules and when it’s better to keep using Framework Manager.
From its humble beginning as a command to “Upload external data” tucked away in Report Studio, data modules has evolved from a simple way to upload and join XLS/CSV files to packages to a powerhouse of a tool. It brings a fresh new look to creating packages and sources for reporting, dashboards, explorations and stories. With it, you can create packages from nearly any source. Whether you are connecting to a database directly, using an existing package or uploading files, data modules is the tool to use.
Data modules is web based: work anywhere, anytime
Framework Manager is a 32-bit Windows application that requires installation on your desktop. Conversely, data modules is an integral part of the Cognos portal and can be used from any location with nothing more than a web browser. This gives you the freedom to work from any machine at any time.
Is it time to retire Framework Manager?
Does the existence of data modules mean that you can or should abandon Framework Manager tomorrow and start doing all new development in data modules? Not quite yet. As one of the newer tools in the Cognos toolbox, there are still some things to work out in the product before we see FM ride off into the sunset completely. For the time being, both tools will be part of your arsenal for creating packages. Let’s look at some of the things you can and cannot do with data modules at this time.

Data modules: what you can do
File uploads: Data modules is an excellent way of getting extra data into reports that normally might not be available. The ability to upload XLS/CSV/TXT files is probably the first way most people will experiment with data modules. This handy feature lets you bring in just about any file in your organization.
As we all know, not everything that requires reporting is easily accessible in a database. The ability to upload files lets you remove that roadblock and get back to producing output for your users. With each new release, this feature gets more robust.
As of 11.1.5, uploading files currently allows for things like
- Using multi-sheet Excel files (each sheet is brought in as its own table)
- Expanded delimited file support (.csv, .tsv, .tab, .txt)
- Uploading compressed files (.zip, .gz)
- Addition of Jupyter Notebook files (.ipynb)
IBM is putting solid development effort into data modules and continually adding to the upload functionality. After a file is uploaded, it can be used in a data module to create a standalone package or to connect to other objects. This functionality allows you to connect it to other uploaded files, existing packages or other data modules.
Modeling: For those not interested in uploading files, data modules should still be considered as your first approach to modeling. Data modules can be used with a Data Server connection. Data Servers are defined database connections that exist in the Cognos environment. These are typically created by your administrator or delegated super user.
Using a data server is going to feel familiar to most folks. It is the same as starting a new project in FM and connecting to a data source. The process starts out with picking a schema and then either choosing tables to bring in manually, or allowing Cognos to examine the data and bring in tables on its own using the Discover Tables feature.
Caveat: Careful when using Discover Tables. It is a robust feature that uses natural language processing and AI-based functionality to examine all of the tables in the source. If you have an extremely large data source, using it can be a taxing process. It may also return too much information to work with easily. Discover Tables looks at the source data and attempts to pull important keywords from it. It creates a word cloud based on the number of times a keyword appears using the size of the words to indicate their frequency of appearance.

Once you’ve chosen the words important to you, the related tables are returned as one or more proposals for you to select.
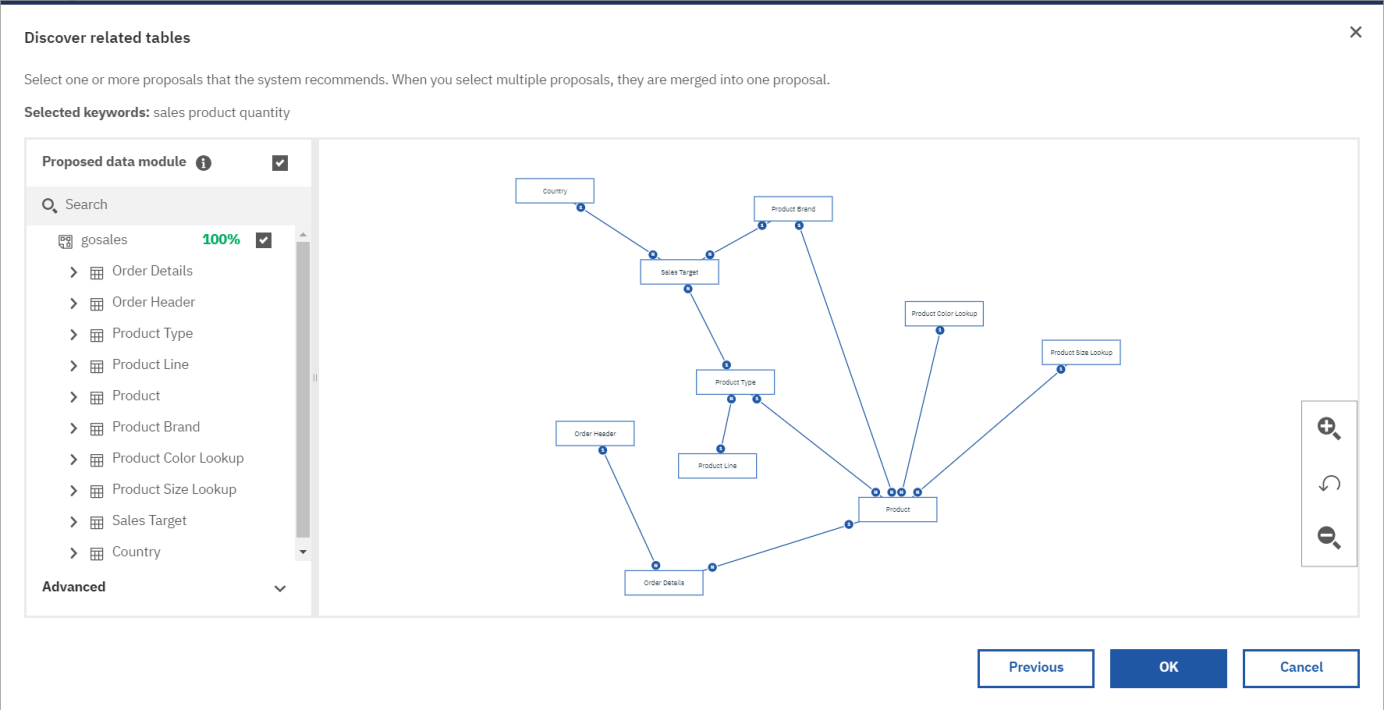
The Discover Tables feature is good for smaller databases; however, it may be less confusing to manually select your tables. The choice will depend on your knowledge of the source data, how large the data server connection is and how complex the schema. The more in line with a standard Kimball star-schema design, the easier Discover Tables can be in returning usable results.
After you have imported your tables, the modeling work begins. If there are clear keys defined in the source tables, DM will automatically join the tables and attempt to identify the cardinality. As with FM, if you allow DM to make joins, you should review to verify it has selected the right fields and identified the relationship properly. From here you can flatten Snowflake tables into their own tables to eliminate cardinality issues, rename fields, set object properties, create subset views of data and all other things you currently do in FM. The resulting data module can then be given to authors and users alike for data analysis. Just like you do today in FM.
Data modules: what you cannot do
At this point you’re thinking that this all sounds great and you’re ready to stop using that old 32-bit product and jump right into the exciting interface of data modules. Not so fast! Now for the currently existing gotchas with data modules that might hinder your modeling.
Issues with the UI: Because data modules is a web-based application, there are some issues with the interface. For example, if your data contains multi-byte character fields, they may not display properly. This same issue may also occur when doing a table merge. If the same field name occurs in multiple tables (such as Product Number in table 1 and table 2), the preview may not show data.
Another interface related issue is the inability to create namespaces. While you can create folders to help organize your tables, you can’t have the display work area zoom in on a specific folder. In a relatively straight forward model, this issue won’t present too great a problem, but if you have hundreds of tables or a low resolution display, locating exactly what you are working with can be difficult.
Technical issues: From a more technical perspective, there are some issues that may be show-stoppers for more complex data sources and business requirements. For example, it’s common for modelers in Framework Manager to use inherited joins to create flattened tables. These flattened tables result in “true dimension” tables, allowing for a 1:1 cardinality against a “true fact” table. By flattening, you can eliminate unwanted query splits in the final package and reports.
Unfortunately, data modules cannot pull this off so elegantly. For example, take the following table structure:
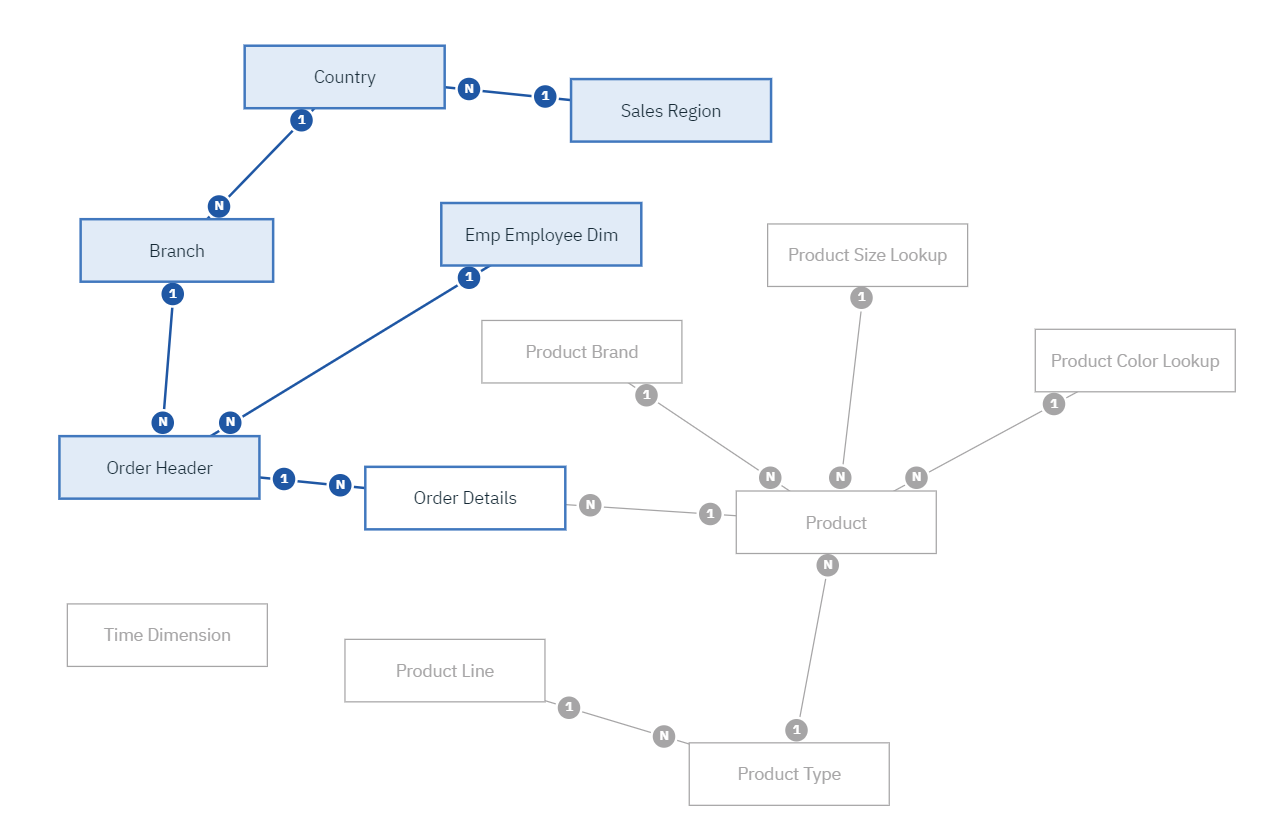
Three dimension tables – Branch, Country and Sales Region – all connect to the Order Header fact table. We would want to flatten these into a single “Branch” dimension table. If were to add the Employee dimension to the flattened table, it would not inherit the join that is already established in Order Header. Employee will need to be kept out as a separate table and as a result we’ll have more subject areas than originally desired. That’s not the end of the world, but what if we only wanted to pull one field from Employee? Now we have an entire extra subject area with only a single entry, which is confusing to our module’s end user.
Data modules also have some similar problems when alias tables are needed. For example, to connect multiple time dimensions for reporting, you need to create multiple views of the tables—versus bringing in the source table twice in FM. Data modules do not provide any shortcuts or alias shortcuts.
Security. Security is another area where FM still has an advantage. While you can create data-level security based on users, groups and roles in a data module, a glaring feature missing at this time is parameter maps. Modelers use parameter maps to narrow down who has access to what data. Importing information from a text file or referencing an existing query subject for parameter maps is a quick, elegant way of applying security to a model. Data modules filtering feels clunky in comparison.
Maintenance nightmares and other possible deal breakers
While some of these issues may seem minor, they can add up to a maintenance nightmare. Speaking of maintenance, at present the concept of branching/merging models is not present in data modules. Organizations with multiple modelers working on different subject areas from the same project will find this a deal breaker. For those who use their model with governors, they too are not present in DM today. When added up, some of these issues will definitely give pause to those who need a full scale enterprise model and packages.
For a litmus test of how well—or not—data modules performs against FM, we took our intensive Framework Modeler Best Practices training class and attempted to recreate the exercises using data modules. Because this class produces a “production ready” set of packages from the IBM GO Sales dataset, it provided a good testing environment. In the end, we were able to complete about 75% of the class demos as a data module. The resulting module was usable for dashboarding and reporting, but not quite as robust or simple to maintain and modify later as the packages created from Framework Manager.
Farewell…eventually…to Framework Manager
Regardless of how much Framework Manager may feel like an old friend and trusted companion, data modules is here to stay. It is anticipated that, one way or another, IBM will address many of the current missing features in future releases. Remember, IBM is putting solid development effort into this tool and wants it to be your go-to modeling environment.
While we can’t say for certain that you could switch all of your modeling over tomorrow, we would recommend you give data modules a try the next time you need to create a package for your groups. The flexibility and ease of use may change your mind about the whole modeling experience.
Want a deeper dive?
See our demo and comprehensive comparison between Framework Manager and data modules. It’s your chance to see for yourself where data modules outshine Framework Manager and where FM remains the better tool.
If you want to get started learning data modules, we offer Cognos Data Modeling with Data Modules training. Choose from self-paced, instructor-led online, custom and onsite.
And, our three-day Framework Manager Metadata Modeling Best Practices course is a fan favorite.