Hierarchies in IBM Planning Analytics are a great tool for providing summarized information that does not exist in the underlying cube. But like Clint Eastwood in arguably the best spaghetti western ever made, this good guy can be tough and gritty in places. Here’s our take on the good, the bad, and the ugly with this powerful feature.
The good
Analytics
The power of a hierarchy in IBM Planning Analytics is the ability to analyze information about a single dimension across multiple axes. In the example below, there is a single, multi-year time dimension with Month-Year detail periods. Each time period has a Quarter and Year attribute, which when used as hierarchies behave like virtual dimensions, providing summarized information that does not exist in the underlying cube. Hierarchies can be used to enrich the analysis of products, customers and any other dimension with descriptive attributes.
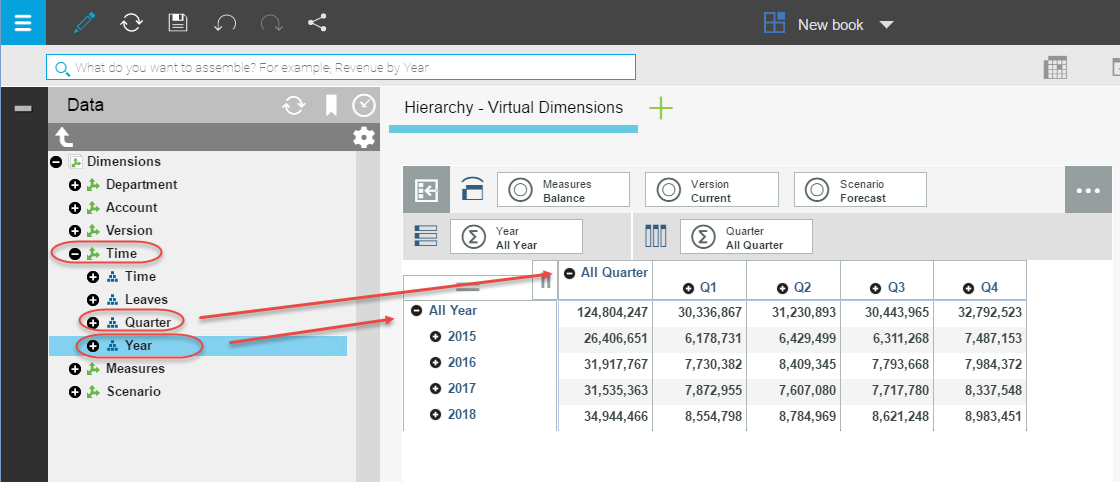
Ease
Hierarchies can be created in moments with just a few button clicks. No coding is required, and no structural changes are made to any cube using the underlying dimension.

Performance
Hierarchies can improve query performance and consume less memory than adding additional dimensions to a cube.
Self-Service
Workspace users can create hierarchies, and then immediately begin creating content and visualizations leveraging the enriched analytics.
The bad
Static Structure
Hierarchies are static; as you add or update elements in the underlying dimension, associated hierarchies are not refreshed.
- New dimension elements are not added to the hierarchy.
- Changed hierarchy attributes for dimension elements are ignored. The hierarchy will still reflect the original attributes.
- Dimension elements deleted using a legacy tool (Performance Modeler or Architect) remain in the hierarchy.
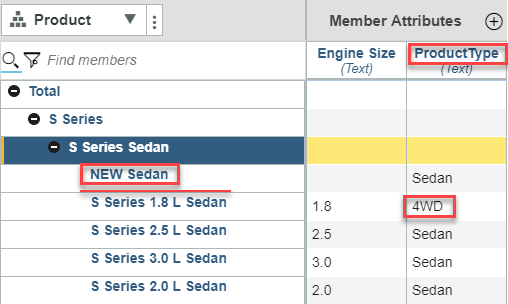
Example: Product Dimension
- Add ‘NEW Sedan’
- Delete ‘S Series 3.4 L Sedan’
- Update ProductType attribute: Sedan > 4WD
Product dimension after updates:
Product Type hierarchy after dimension updates:
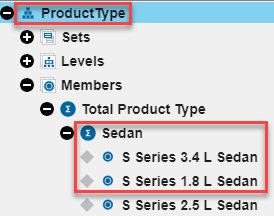
None of the dimension updates are reflected in the Product Type hierarchy. Consequently, views and visualizations using hierarchies may not reflect the current state of the underlying dimension. We cannot think of any use case where you would want a hierarchy to be out of synch with the underlying dimension, so this is a bit disappointing.
Level Names
The best practice is to assign descriptive names to the levels of a hierarchy, but the Workspace interface does not provide this capability. Workspace populates the same generic level names for every hierarchy.

Presenting users with descriptive level names requires making updates directly to a control cube (i.e. a hidden, system-managed cube) and writing a bit of code. A user must have developer capabilities to present level names as shown.

Self-Service
While the self-service management of hierarchies can empower analysts using Workspace, it can also create problems. Hierarchies are maintained on the server and are accessible by all. As such, they are effectively production objects, but with no change control. Actions by one self-service author could impact or cause errors in the analyses and content of others.
The ugly
Maintenance
Keeping with the self-service approach, the recommendation for updating hierarchies is to delete them and recreate them. Unfortunately, this approach can lead to errors or unintended changes to content because Sets created for the hierarchy are lost and the virtual dimension is removed from views and visualizations.
The alternative is to develop complex code to keep hierarchies in sync with the underlying dimension without impacting existing Sets and content. This method is the most reliable and allows for the development of persistent content that accurately reflects current hierarchies. However, it effectively precludes self-service as it requires centralized control.
Tips
To avoid some of the pitfalls described above, consider the following tips.
- Carefully manage the creation and maintenance of hierarchies.
- Ensure that the last step in dimension maintenance is to synchronize hierarchies for any changes.
- Be mindful of your production environment. Evaluate the degree to which you will allow Workspace users (as opposed to administrators and developers) to create and alter hierarchy objects shared by all.
- Use self-service administration of hierarchies for ad hoc analysis as opposed to persistent content.
Hierarchies are an important tool for extending analytical and reporting capabilities without structural and code changes to the TM1 cube…but there are a few warts to be aware of. Practice these tips and you’ll maximize the good and avoid some of the bad and ugly. You may also be interested in our on-demand webinar on IBM Planning Analytics 2.0 that covers Planning Analytics Workspace and integration with Cognos Analytics in addition to hierarchies.
Thanks to our own Ken O’Boyle for this post. Ken is our lead planning consultant and a specialist in TM1/ IBM Planning Analytics and is a regular contributor to our webinars and blogs. He has more than 20 years of hands-on experience architecting, implementing and delivering training for enterprise planning, business intelligence and data warehousing solutions. He also provides training on TM1.