The Snowflake phenomenon
Snowflake has become a phenomenon across industries with its focus on analytical data storage and impressive performance. With compute capacity paid on a consumption basis and most legacy performance tuning now handled by the service, increasing performance is often as simple as spending a bit more money. But as easy as Snowflake makes it to boost performance, there are some tweaks you can make to ensure you are getting the best bang for your Snowflake buck. We offer up seven places Snowflake performance can get hung up, the tips to get around them and the tool for identifying where the issues are. With these techniques you can wring out the most cost-effective Snowflake implementation possible.
Identifying slowdowns: using Snowflake Query Profile
The first step to Snowflake optimization is to discover the source of performance bottlenecks. Use Snowflake’s Query Profile tool to diagnose issues in slow running queries. Like similar database management tools, Query Profile lets you explore how Snowflake executed your query and what steps in the process are causing slowdowns.
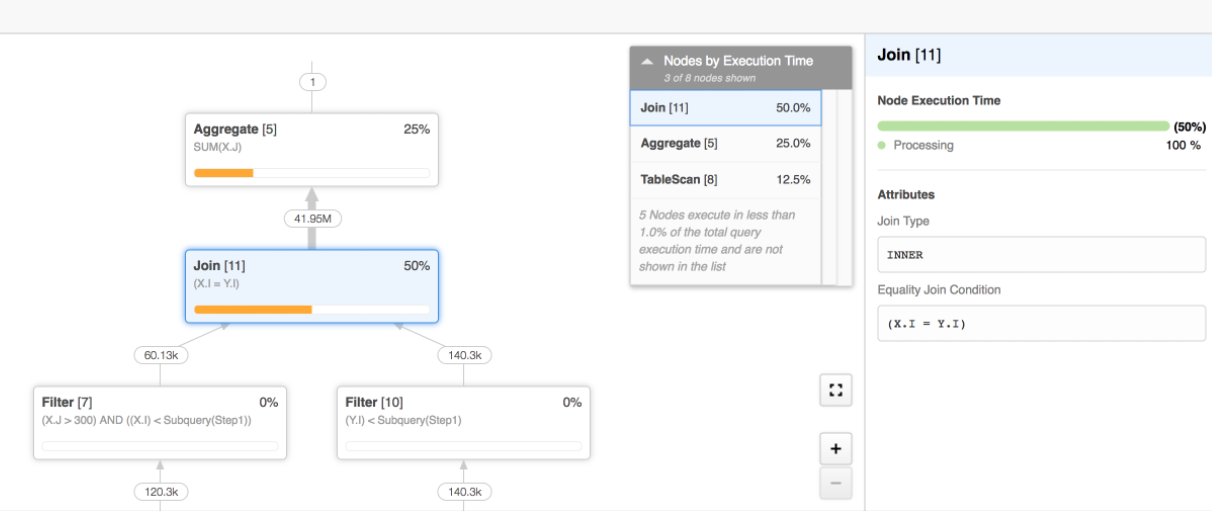
Once you have identified the nature of the problem, use these seven best practices to help optimize your query speed and overall Snowflake performance.
Snowflake vs. Azure: see the video
#1. Dedicate compute warehouses by use case
Depending on the use case, scaling out compute capacity (more concurrency) can be more cost effective and beneficial than just scaling up (more performance). Size each compute warehouse appropriately, isolate by use cases, and auto-suspend as reasonable. For example, if all data loading happens in the morning then that capacity should be suspended the rest of the day. If data loading is taking too long, scale up for more speed on a single data source or scale out when concurrently loading multiple sources.

#2. Select only required data columns
Selecting only the data columns needed will optimize performance by minimizing the amount of data being read and transferred.
- Avoid select * queries
- When practical, let visualization tools generate SQL to execute queries instead of hard coded-custom SQL queries. A lot of vendor intelligence has gone into generating optimal SQL queries based on visualizations.
#3. Leverage materialized views
Materialized views can improve the performance of queries that repeatedly use the same subquery results. Use materialized views when
- The query contains a small number of rows and/or columns relative to the base table
- The query contains results that require significant processing
- The query is against file-based data
- Results don’t change often
- Results are used often
- The query consumes a lot of resources
You can create a materialized view like this:

And use it like this:
![]()
But be careful! There are some gotchas:
- A background service automatically updates the materialized view after changes are made to the base table
- The maintenance of materialized views consumes credits
- Compare materialized views vs. scaling up compute to solve performance issues
#4. Watch for exploding joins
Joins can create very slow query performance under the following conditions:
- Joins that lack a condition (i.e. “ON col_1 = col_2”)
- Joins where records from one table match multiple records in the joined table—this state causes a “Cartesian Product” when executing
During query execution in these situations, the JOIN operator produces significantly more (often by orders of magnitude) tuples than necessary.
Proper modeling of data in the warehouse will minimize the occurrence of exploding joins. Materialized Views may also be an appropriate solution under certain conditions and use cases.
When an exploding join cannot be avoided, there are techniques to solve the performance problem.
Assume this query has slow join performance:

Solve with temporary tables:

Solve with nested SELECT:

#5. Define clustering keys on large tables
In general, Snowflake produces well-clustered data in tables. Over time, particularly on very large tables, the data in some tables may no longer be optimally clustered on desired dimensions. Snowflake supports automatic re-clustering data based on user defined clustering keys.
Define clustering keys when queries on the table are running slower than expected or have noticeably degraded over time.
A clustering key can contain one or more columns, with a Snowflake suggested maximum of four columns. Analyze common queries in your workload to select the right clustering key columns based on columns used in joins and filters.
There are some gotchas
- “Cluster by” columns should not have very low cardinality (only 2 or 3 possible values)
- “Cluster by” columns should not have very high cardinality (every row has a different value)
- Re-clustering consumes compute credits
- Clustering keys consume additional storage costs
#6. Avoid UNION without ALL
Use SQL query with UNION ALL whenever possible. Combining just two result sets, the UNION ALL option is fast.
On the other hand, the SQL query with UNION option combines results and then scans that complete result set to remove any duplicates, making it slow and resource intensive.
Example:

is faster than

#7. Queries too large to fit in memory
Certain expensive operations (like duplicate elimination) exceed the amount of memory allocated to the compute instance. This data will begin spilling to the local disk, then to remote disks. You can experience major performance degradation.
Solutions include:
- Using a larger compute warehouse with more resources (temporary or permanent)
- Processing data in batches, then combine results
- Aggregating tables during the data modeling process
Keep in mind that larger compute warehouses will cost more. Use auto-suspend and auto-scaling strategies to control costs.
Getting speed and cost effectiveness from Snowflake
Snowflake is a powerful SaaS data warehouse that internally handles most traditional administrative and performance tuning tasks. Using the seven techniques provided here will go a long way towards ensuring you are getting peak performance from your Snowflake implementation while also doing a favor to your pocketbook.
View our on-demand webinar 10 Reasons Snowflake Is Great for Analytics.
Senturus is a Snowflake partner with expertise across many BI technologies. We are here to help you get the most out of your Snowflake implementation and entire analytics environment. Contact us.